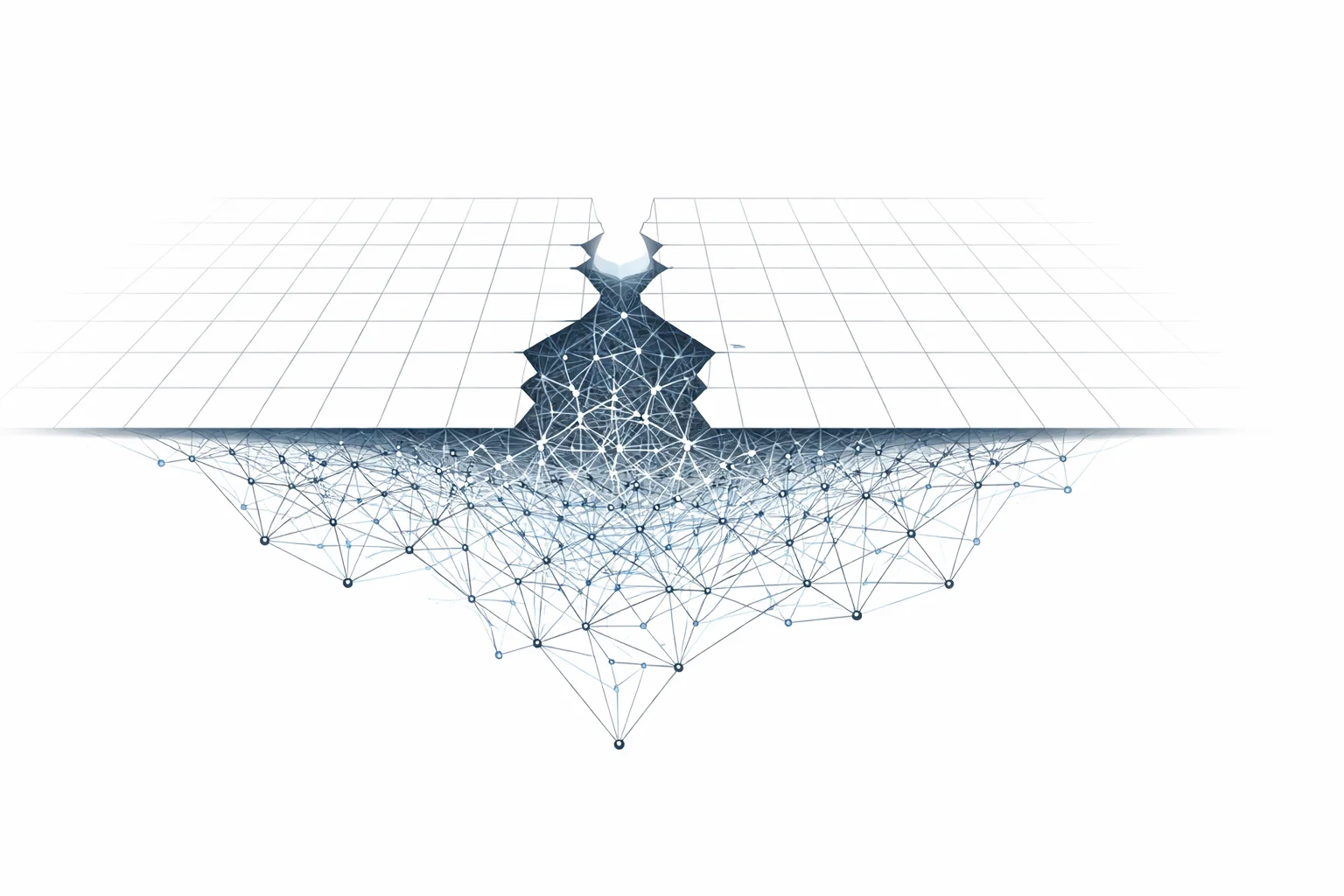
Where Spark Changes Shape: UnsafeRow, the JVM, and the Relocation of Portability
Run df.explain on a Parquet scan and you find ColumnarToRow, an operator whose only job is to change the data’s shape. It is the seam where two architectural eras meet, and a record of how portability in analytical systems has relocated from the JVM runtime to the data format and the query plan.